With my dev hat on, my workday looks very different from what it looked like two years ago.
I still read code, trace bugs, write patches, run tests, and try fixing build systems. But a lot of the mechanical back-and-forth now happens through coding agents. I keep long-running project context warm and let the agent inspect files, propose changes, run commands, read failures, revise, and try again. I jump in when judgment is needed, when the direction is wrong, or when the model needs a sharper pivot.
On a normal day, that workflow can cross 300M tokens. On heavy days, it has crossed 1B tokens.
That is not a badge of honor by itself. If anything, the first reaction should be suspicion. A billion tokens can mean focused engineering work, but it can also mean a bad loop, noisy context, or an expensive way to avoid thinking. The number only becomes interesting when you look at its shape.
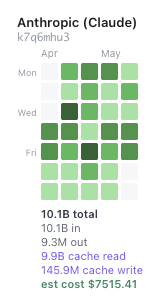
One of those days, the outgate.ai console showed roughly 2K requests, 1B prompt tokens, 1M completion tokens, and an estimated $558 of model cost from token usage. That ratio is the story. The model was not producing a billion tokens of code. It was repeatedly reusing stable project context while doing the kind of work developers actually do: reading, navigating, testing, failing, revising, and checking assumptions inside a real codebase.
This is where the pricing conversation becomes uncomfortable. The same workflow that feels cheap inside a $20, $100, or $200 individual subscription can become a visible infrastructure bill when a company runs it through API pricing, enterprise contracts, shared workspaces, or governed agent platforms. Over the past month, if I had been billed purely per token, I would have paid $7,515.41 in token cost alone.
It is not simply that subscriptions are cheaper and APIs are more expensive. The two pricing models describe different realities. The subscription model gets devs hooked. The token model exposes the real cost to companies.
Coding agents are starting to look like cloud infrastructure.
The Subscription Illusion
Individual AI subscriptions trained us to think about coding AI as a fixed monthly expense. For normal non-business users, the product is usually not sold as a seat in the enterprise sense. It is sold as a personal subscription: pay a monthly fee, open the editor or terminal, and use the model until a message, session, credit, or weekly limit appears.
That model works for adoption. It is simple, predictable, and psychologically comfortable. The important detail is that these plans rarely promise a hard number of tokens. They are marketed as access privileges: more usage than the free plan, higher limits, priority access, extended thinking, more agentic capacity, or "5x" and "20x" style tiers. That language is not accidental. The user buys a feeling of abundance, not a fixed token entitlement.
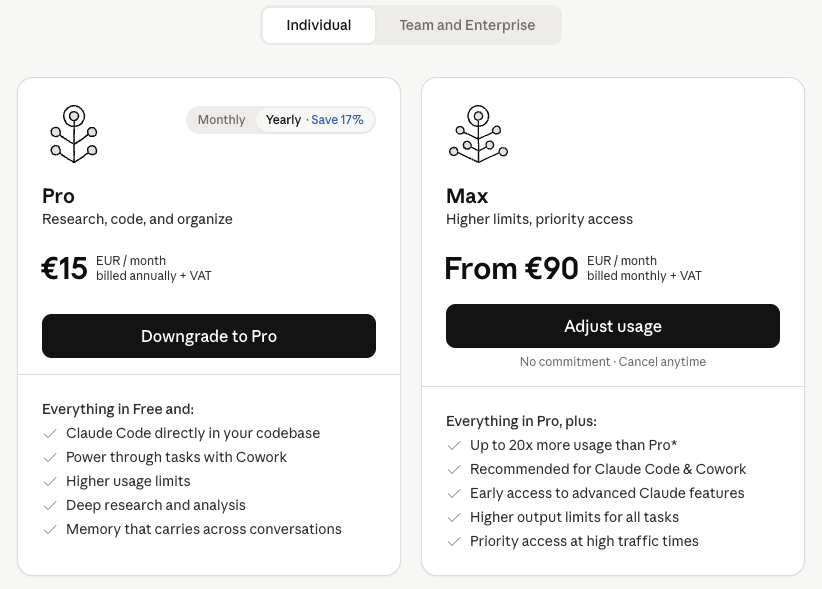
Anthropic's public pricing for its consumer plans lists fixed monthly subscriptions for Pro and Max tiers, while its usage documentation explains that limits vary by model, message length, file uploads, conversation length, and capacity conditions. For Claude Code specifically, Anthropic says API usage is charged by token consumption and gives enterprise averages around $13 per developer per active day and $150-250 per developer per month, while noting large variance depending on model selection, codebase size, multiple instances, and automation. [1][2][3]
OpenAI has moved in the same direction for Codex. Its docs say pricing is aligned with API token usage rather than per-message pricing. OpenAI's API pricing also separates input, cached input, and output tokens, which is exactly the accounting model that matters for long-running agentic work. [5][6]
The raw token economics make the gap visible. As of May 2026, frontier API pricing commonly separates fresh input, cached input, and output. Anthropic lists current Claude Opus pricing at $5 per million input tokens, $0.50 per million cache-read tokens, and $25 per million output tokens, with Sonnet lower at $3, $0.30, and $15 respectively. OpenAI's API pricing similarly lists frontier and coding models with separate input, cached-input, and output rates. This is why a high-cache billion-token day can look very different from a low-cache billion-token day. The same headline token volume can represent either efficient repeated use of stable context or very expensive context churn. [4][6]
GitHub Copilot, Cursor, and Google Gemini Code Assist show the same pattern from different angles. Copilot plans still look like per-user subscriptions, but GitHub documents premium requests and paid overage mechanics for heavier usage. Cursor describes included usage in API-cost-backed terms and says model selection affects how quickly included usage is consumed. Google packages Gemini Code Assist Standard and Enterprise as organizational products with security, administration, and SDLC integration. [7][8][9]
The pattern is clear: the front door is still a subscription, but the back end is increasingly metered compute. For light users, the subscription hides this nicely. For heavy agentic users, the meter eventually reappears as a limit, downgrade, queue, credit balance, overage, or enterprise invoice.
Engineering Output Was Already Uneven
The pricing problem is sharper because engineering output has never been evenly distributed.
The old "10x engineer" phrase is often abused. It can become a lazy way to ignore team design, codebase quality, review load, product clarity, and organizational friction. But the underlying observation is not imaginary: software productivity varies a lot. The classic Sackman, Erikson, and Grant study reported very large differences between programmers on controlled tasks, and later discussions have criticized the methodology while still treating high variance as a real phenomenon in software work. [10]
Modern productivity frameworks also warn against reducing developer output to a single number. DORA and the SPACE framework both push toward multidimensional measurement: flow, quality, satisfaction, delivery, collaboration, and business outcomes all matter. DORA's 2025 report, based on nearly 5,000 technology professionals, found AI is now broadly present in software work, but also highlighted a trust gap and the need for organizational capabilities around AI adoption. [11]
That matters for token budgets.
A junior engineer asking isolated questions, a staff engineer running a multi-repo migration or team agents, a platform engineer debugging a distributed incident, and a security engineer using agents to audit dependency risk will not have the same token profile. Their usage should not be expected to average out neatly.
The market is still missing good public data on "average tokens per engineer per day," let alone "tokens per top-decile engineer." Vendor averages are useful, but they are not a productivity benchmark. Anthropic's enterprise averages tell us something about spend distribution, not engineering impact.
The right conclusion is not "more tokens means better engineer." The right conclusion is that serious engineering work is bursty, context-heavy, and uneven, so token limits that treat everyone the same will often be wrong.
This is where subscription pricing and token pricing pull in opposite directions. A subscription wants usage to look smooth: one person, one plan, one monthly price. Engineering work is not smooth. It comes in bursts: a migration week, an incident, a refactor, a launch, a security review, a new codebase, a broken test suite. Token pricing reflects that burstiness immediately. Subscription pricing hides it until the user hits the invisible wall.
The Dangerous Corporate Reaction: Cap, Downgrade, Normalize
When AI bills rise, the first reaction is usually predictable: cap usage, downgrade models, centralize procurement, or force everyone onto the same approved assistant.
Some of that is necessary. Unbounded agent loops can waste money quickly. A poorly scoped background task can burn through tokens without useful work. The Stanford-led agentic coding cost paper is especially important here because it shows both high cost and weak predictability. Budget-aware policies are not optional for production AI. [12]
But blunt controls create a different failure mode.
If a company downgrades frontier coding models for everyone, caps high-leverage users at casual-use limits, or makes approved tools materially worse than personal subscriptions, developers will route around the system. They will use personal accounts, unmanaged browser sessions, copied code snippets, and local API keys. That is bad for productivity and worse for security.
The cost saving then becomes fictional. The company does not eliminate the usage. It loses visibility into it.
For engineering organizations, the better question is not "How do we reduce token usage?" It is:
How do we spend expensive tokens only to increase engineering creativity?
Enterprise Pricing Buys More Than Tokens
This is why enterprise AI pricing can look unfair from the outside.
An individual sees a $20 or $200 subscription and asks why a company should pay more. But organizations are not just buying access to a model. They are buying administrative control, predictable availability, contractual terms, shared billing, auditability, security posture, data controls, support, and policy enforcement.
GitHub Copilot Business and Enterprise differentiate on organizational management, policy controls, enterprise features, and indemnity. Cursor Teams and Enterprise add centralized billing, SSO, privacy mode, usage analytics, audit logs, pooled usage, model controls, and support. Google Gemini Code Assist Enterprise adds enterprise SDLC integration and code customization. [7][8][9]
Anthropic and OpenAI expose the same enterprise reality through usage-based billing, workspace credits, API token accounting, cached-token pricing, and spend controls. [2][5][6]
This is not just vendor margin. Some of it is the real cost of making AI safe and operable inside a company.
The problem is that many organizations still buy these tools like seats while developers use them like compute clusters.
That creates a translation problem inside the company. Finance wants a per-user subscription number. Engineering wants frontier models available at the moments when they matter. Security wants control over data leaving the environment. Platform wants one integration pattern instead of every team wiring its own keys. The provider's token meter is precise, but it is too low-level for organizational planning. The subscription is easy to buy, but it is too vague for operational control.
The gap is therefore not only economic. It is organizational. Someone has to translate between "this developer has a plan" and "this workflow consumed expensive frontier inference against this repo, with this cache behavior, under this privacy policy, producing this engineering result."
The GDPR and Data Privacy Problem
For European companies, the pricing question cannot be separated from data protection.
Coding agents do not only process prompts. They may process source code, logs, stack traces, database samples, tickets, customer identifiers, employee names, API responses, internal documentation, credentials, and production error output. Some of that can be personal data. Some of it can be confidential business information. Some of it can be both.
The European Data Protection Board's Opinion 28/2024 on AI models emphasized that GDPR principles apply when personal data is processed in AI model development or deployment, and that organizations need to assess anonymity, legal basis, legitimate interest, and downstream processing carefully. The EDPB also stressed documentation and technical and organizational measures. [13][14]
For coding agents, that translates into practical questions:
- What personal data is entering prompts, files, tool outputs, and logs?
- Is the model provider a processor, controller, or independent provider in this context?
- Is the data used for training, abuse monitoring, debugging, or only transient inference?
- Where is the data processed?
- What is retained?
- Can sensitive values be minimized, pseudonymized, blocked, or rehydrated safely?
- Can the organization prove what happened after the fact?
Pseudonymization is not magic anonymization under GDPR. Redacting or replacing values helps, but companies still need to think about reversibility, key management, access control, and whether data can be linked back to an individual. The right privacy architecture is not "send everything to the model and trust the contract." It is data minimization, purpose limitation, access control, and auditability applied directly in the AI request path.
This is where a gateway becomes more than a cost tool.
What Outgate Changes
Outgate sits between developers, agents, and model providers. That position matters because it is where the real operational decisions happen.
Instead of forcing every developer to choose between an unmanaged personal subscription and a locked-down enterprise assistant, Outgate gives the organization a control layer for AI traffic:
- Route coding-agent traffic across approved providers and models.
- Keep developers in familiar tools such as Claude Code, Codex, and terminal-based agents.
- Apply PII and credential guardrails before requests reach upstream providers.
- Use anonymization, blocking, vault matching, and response rehydration where appropriate.
- Track requests, latency, success rates, token usage, cache behavior, and estimated cost.
- Enforce budgets by user, team, project, provider, model, or workflow.
- Support regional deployment patterns for organizations that need stronger data-boundary control.
- Give platform, security, and finance teams one place to observe and govern usage.
That is the missing layer between "everyone gets a subscription" and "everything is raw API spend."
In other words, Outgate is not trying to pretend the gap does not exist. It makes the gap governable. Developers can keep the high-leverage agentic workflows that personal subscriptions made them expect, while the company gets the operational language of token pricing: provider, model, cache, cost, latency, success rate, policy result, and data boundary.
The goal should not be to stop high-token engineering work. The goal should be to understand it well enough to govern it.
If a senior engineer burns millions of cached input tokens resolving a production issue faster, that may be a good trade. If an agent burns the same amount repeatedly failing a poorly specified task, that is waste. If sensitive customer data enters an unmanaged model session, that is a governance failure regardless of whether the task succeeds.
Outgate helps make those differences visible.
Sources
- [1] Anthropic Support, "Choosing a Claude.ai plan": https://support.claude.com/en/articles/11049762-choosing-a-claude-ai-plan
- [2] Anthropic Claude Code Docs, "Manage costs effectively": https://code.claude.com/docs/en/costs
- [3] Anthropic Support, "Manage usage credits for paid Claude plans": https://support.claude.com/en/articles/12429409
- [4] Anthropic API Docs, "Pricing": https://platform.claude.com/docs/en/about-claude/pricing
- [5] OpenAI Help Center, "Codex rate card": https://help.openai.com/en/articles/20001106-codex-rate-card
- [6] OpenAI Platform Docs, "API pricing": https://platform.openai.com/docs/pricing/
- [7] GitHub Docs, "Plans for GitHub Copilot": https://docs.github.com/en/copilot/get-started/plans
- [8] Cursor Docs, "Pricing and usage": https://cursor.com/docs
- [9] Google Cloud, "Gemini for Google Cloud pricing": https://cloud.google.com/products/gemini/pricing
- [10] O'Reilly, "Individual Productivity Variation in Software Development" in Making Software: https://www.oreilly.com/library/view/making-software/9780596808310/ch30s01.html
- [11] DORA, "State of AI-assisted Software Development 2025": https://dora.dev/research/2025/dora-report/
- [12] "How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks": https://arxiv.org/abs/2604.22750
- [13] European Data Protection Board, news release on Opinion 28/2024: https://www.edpb.europa.eu/news/news/2024/edpb-opinion-ai-models-gdpr-principles-support-responsible-ai_en
- [14] European Data Protection Board, Opinion 28/2024: https://www.edpb.europa.eu/our-work-tools/our-documents/opinion-board-art-64/opinion-282024-certain-data-protection-aspects_en